概述
Java 8 引入了全新的 Stream API,此 Stream 与 java I/O 包里的 InputStream 和 OutputStream 是完全不同的概念,它不同于 StAX 对 XML 解析的 Stream,也不同于 Amazon Kinesis 对大数据实时处理的 Stream。Stream API 更像具有 Iterable 的集合类,但行为和集合类又有所不同,它是对集合对象功能的增强,专注于对集合对象进行各种非常便捷、高效的聚合操作或大批量数据操作。
Stream API 引入的目的在于弥补 Java 函数式编程的缺陷。对于很多支持函数式编程的语言,map()、reduce()基本上都内置到语言的标准库中了。不过,Java 8 的 Stream API 总体来讲仍然是非常完善和强大,足以用很少的代码完成许多复杂的功能。
Java 8 的 Stream API 充分利用 Lambda 表达式的特性,极大的提高编程效率和程序可读性。同时它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势,使用 fork/join并行方式来拆分任务和加速处理过程。通常编写并行代码很难而且容易出错,但使用 Stream API 无需编写一行多线程的代码,就可以很方便地写出高性能的并发程序。
在 Stream API 中,一个流基本上代表一个元素序列,Stream API 提供了丰富的操作函数来计算这些元素。以前我们在开发业务应用时,通常很多操作的实现是这样做的:我们使用循环对集合做遍历,针对集合中的元素实现各种操作,定义各种变量来实现目的,这样我们就得到了一大堆丑陋的顺序代码。
如果开发过程中使用 Stream API 做同样的事情,使用 Lambda 表达式和其它函数进行抽象,可以使得代码更易于理解、更为干净。有了这些抽象,还可以做一些优化,比如实现并行等。
什么是 Stream
Stream(流)是一个来自数据源的元素队列并支持聚合操作。
元素:特定类型的对象,形成一个队列。Stream 并不会存储元素,而是按需计算。
数据源:流的来源。可以是集合,数组,I/O channel,产生器 generator 等。
聚合操作:类似 SQL 语句一样的操作,比如 filter、map、reduce、find、match、sorted 等。
Stream 不是集合元素,它不是数据结构并不保存数据,它是有关算法和计算的,它更像一个高级版本的 Iterator。原始版本的 Iterator,用户只能显式地一个一个遍历元素并对其执行某些操作;高级版本的 Stream,用户只要给出需要对其包含的元素执行什么操作,Stream 会隐式地在内部进行遍历,做出相应的数据转换。Stream 就如同一个迭代器(Iterator),单向,不可往复,数据只能遍历一次,遍历过一次后即用尽了,就好比流水从面前流过,一去不复返。Stream 和迭代器又不同的是,Stream 可以并行化操作,迭代器只能命令式地、串行化操作。顾名思义,当使用串行方式去遍历时,每个 item 读完后再读下一个 item。而使用并行去遍历时,数据会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出。Stream 的并行操作依赖于 Java7 中引入的 Fork/Join 框架(JSR166y)来拆分任务和加速处理过程。
Stream 和 Collection 的区别主要有:
Stream本身并不存储数据,数据是存储在对应的Collection里,或者在需要的时候才生成的;Stream不会修改数据源,总是返回新的Stream;Stream的操作是懒执行(lazy)的,仅当最终的结果需要的时候才会执行。
Stream 和 Collection 相比,Stream 操作还有两个基础的特征:
Pipelining:中间操作都会返回流对象本身。这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。这样做可以对操作进行优化,比如延迟执行(laziness)和短路(short-circuiting)。内部迭代:以前对集合遍历都是通过 Iterator 或者 forEach 的方式,显式的在集合外部进行迭代,这叫做外部迭代。Stream 提供了内部迭代的方式,通过访问者模式(Visitor)实现。
Stream 的使用步骤如下:
- 创建 Stream。
- 通过一个或多个中间操作(intermediate operations)将初始 Stream 转换为另一个 Stream。
- 通过中止操作(terminal operation)获取结果;该操作触发之前的懒操作的执行,中止操作后,该 Stream 关闭,不能再使用了。
Stream 的创建
最常用的 Stream 的创建方式有以下几种途径:
- 通过
Stream接口的静态工厂方法; - 通过
Collection接口的默认方法–stream(),为集合创建串行流。 - 通过
Collection接口的默认方法–parallelStream(),为集合创建并行流。 - 通过
Arrays类的stream()静态工厂方法。
需要注意的是,对于基本数值型,目前有三种对应的包装类型 Stream:
IntStream、LongStream、DoubleStream。当然我们也可以用Stream<Integer>、Stream<Long>、Stream<Double>,但是boxing和unboxing会很耗时,所以特别为这三种基本数值型提供了对应的 Stream。
Java 8 中还没有提供其它数值型 Stream,因为这将导致扩增的内容较多。而常规的数值型聚合运算可以通过上面三种 Stream 进行。
通过 Stream 的静态方法来创建 Stream
Stream 接口提供了几个静态工厂方法用来创建 Stream 对象:
| 方法 | 描述 |
|---|---|
static <T> Builder<T> builder() |
返回一个 Stream 的可变构建器,可通过 Builder 的 build() 方法返回一个 Stream 实例 |
static <T> Stream<T> empty() |
返回一个空的 Stream 实例 |
static <T> Stream<T> of(T t) |
返回一个包含单一元素的 Stream 实例 |
static <T> Stream<T> of(T... values) |
返回一个包含指定元素并且按顺序排列的 Stream 实例 |
static <T> Stream<T> iterate(T seed, UnaryOperator<T> f) |
返回一个无限元素有序的 Stream 实例,其元素的生成是重复对给定的种子值(seed)调用指定函数来生成的,其中包含的元素可以认为是:seed,f(seed),f(f(seed))无限循环 |
static <T> Stream<T> generate(Supplier<T> s) |
返回一个无限元素无序的 Stream 实例,其中每个元素由提供的 Supplier 生成,这适用于生成常量流、随机元素流等 |
static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b) |
创建一个延迟连接的 Stream 实例,其元素是第一个流的所有元素,然后是第二个流的所有元素 |
Stream的iterate()和generate()方法都用于生成无限元素的流,所以一般这种无限长度的Stream都会配合Stream的limit()方法来用。
通过 Collection 子类创建 Stream
Collection 接口提供了2个默认方法用来创建 Stream 对象:
| 方法 | 描述 |
|---|---|
default Stream<E> stream() |
返回一个指定该集合为源的有序的 Stream 实例 |
default Stream<E> parallelStream() |
返回一个指定该集合为源的并行的 Stream 实例 |
通过 Arrays 的静态方法来创建 Stream
Arrays 类提供了几个个静态工厂方法用来创建 Stream 对象:
| 方法 | 描述 |
|---|---|
static <T> Stream<T> stream(T[] array) |
返回一个以指定数组为源的有序的 Stream 实例 |
static <T> Stream<T> stream(T[] array, int startInclusive, int endExclusive) |
返回一个以指定数组的指定范围为源的有序的 Stream 实例 |
static IntStream stream(int[] array) |
返回一个以指定数组为源的有序的 IntStream 实例 |
static IntStream stream(int[] array, int startInclusive, int endExclusive) |
返回一个以指定数组的指定范围为源的有序的 IntStream 实例 |
static LongStream stream(long[] array) |
返回一个以指定数组为源的有序的 LongStream 实例 |
static static LongStream stream(long[] array, int startInclusive, int endExclusive) |
返回一个以指定数组的指定范围为源的有序的 LongStream 实例 |
static DoubleStream stream(double[] array) |
返回一个以指定数组为源的有序的 DoubleStream 实例 |
static DoubleStream stream(double[] array, int startInclusive, int endExclusive) |
返回一个以指定数组的指定范围为源的有序的 DoubleStream 实例 |
Stream 的转换
当把一个数据结构包装成 Stream 后,就要开始对里面的元素进行各类操作了。常见的操作可以归类如下。
中间操作(Intermediate):一个流可以后面跟随零个或多个 Intermediate 操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用,这种操作也叫做惰性求值方法。如:map (mapToInt, flatMap 等)、filter、distinct、sorted、peek、limit、skip、parallel、sequential、unordered;终止操作(Terminal):一个流只能有一个 Terminal 操作,当这个操作执行后,流就被使用“光”了,无法再被操作。如:forEach、forEachOrdered、toArray、reduce、collect、min、max、count、anyMatch、allMatch、noneMatch、findFirst、findAny、iterator。
我们下面看一下 Stream 的比较典型用法。
distinct()
distinct() 方法对于 Stream 中包含的元素进行去重操作(去重逻辑依赖元素的 equals() 方法),新生成的 Stream 中没有重复的元素。
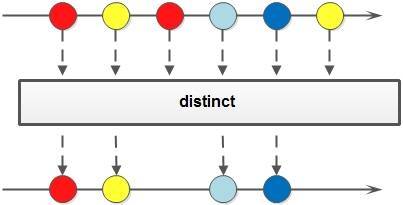
以下代码片段使用 distinct() 方法去除重复的元素并排序后输出:
List<Character> letters = Arrays.asList('A', 'D', 'C', 'B', 'D', 'A');
letters.stream()
.distinct()
.sorted()
.forEach(System.out::println);
如果需要去重的元素是对象,则引用的对象要实现
hashCode()方法和equal()方法,否则去重是无效的。
filter()
filter() 方法对于 Stream 中包含的元素使用给定的过滤函数进行过滤操作,新生成的 Stream 只包含符合条件的元素。
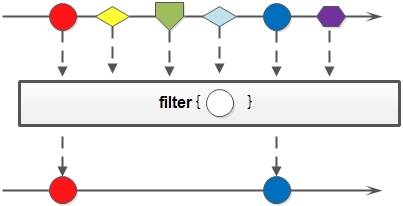
以下代码片段使用 filter() 方法过滤出长度小于5的语言个数:
List<String> languages = Arrays.asList("java", "scala", "python", "shell", "ruby");
long num = languages.parallelStream().filter(s -> s.length() < 5).count();
System.out.println(num);
map()
map() 方法对于 Stream 中包含的元素使用给定的转换函数进行转换操作,新生成的 Stream 只包含转换生成的元素。这个方法有三个对于原始类型的变种方法,分别是:mapToInt,mapToLong 和 mapToDouble。这三个方法也比较好理解,比如 mapToInt 就是把原始 Stream 转换成一个新的 Stream,这个新生成的 Stream 中的元素都是 int 类型。之所以会有这样三个变种方法,可以免除自动装箱/拆箱的额外消耗。
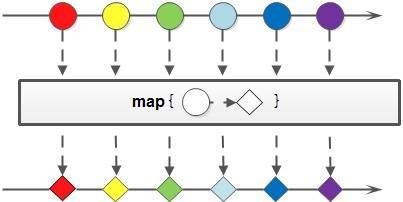
以下代码片段使用 map() 方法得到元素对应的平方数并去除重复元素后转换为集合:
List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5);
List<Integer> squaresList = numbers.stream()
.map(i -> i * i)
.distinct()
.collect(Collectors.toList());
flatMap()
flatMap() 方法和 map() 方法类似,不同的是其每个元素转换得到的是 Stream 对象,会把子 Stream 中的元素压缩到重新生成的集合中。
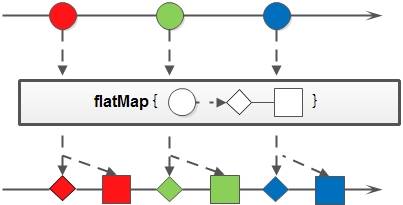
以下代码片段使用 flatMap() 方法将多个 Stream 连接成一个 Stream 并转换为集合后输出:
Stream<List<Integer>> numbersStream = Stream.of(
Arrays.asList(1),
Arrays.asList(2, 3),
Arrays.asList(4, 5, 6)
);
numbersStream
.flatMap(Collection::stream)
.collect(Collectors.toList())
.forEach(System.out::println);
peek()
peek() 方法生成一个包含原 Stream 的所有元素的新 Stream,同时会提供一个消费函数(Consumer 实例),新 Stream 每个元素被消费的时候都会执行给定的消费函数。
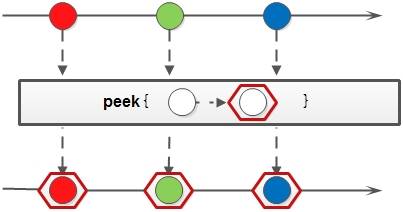
以下代码片段使用 peek 消费了过滤后的元素和转换后的元素:
List<String> peeks = Stream.of("one", "two", "three")
.filter(s -> s.length() < 4)
.peek(s -> System.out.println("Filtered value: " + s))
.map(String::toUpperCase)
.peek(s -> System.out.println("Mapped value: " + s))
.collect(Collectors.toList());
System.out.println("Result value: " + peeks);
limit()
limit() 方法对一个 Stream 进行截断操作,获取其前 N 个元素,如果原 Stream 中包含的元素个数小于 N,那就获取其所有的元素。
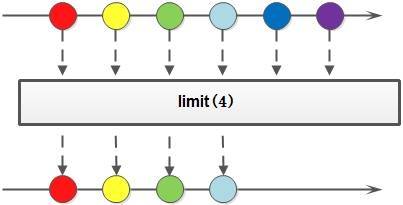
以下代码片段使用 limit() 方法得到前2个元素并输出:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
System.out.println("limit:");
numbers.stream()
.limit(2)
.forEach(System.out::println);
skip()
skip() 方法返回一个丢弃原 Stream 的前 N 个元素后剩下元素组成的新 Stream,如果原 Stream 中包含的元素个数小于 N,那么返回空 Stream。
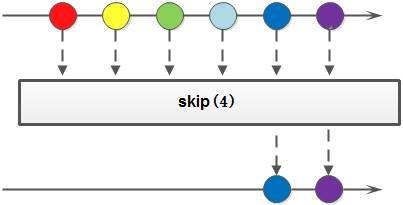
以下代码片段使用 skip() 方法得到前2个元素后剩下的元素并输出:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
numbers.stream()
.skip(2)
.forEach(System.out::println);
reduce()
reduce() 方法用于从 Stream 中生成一个值,其生成的值不是随意的,而是根据指定的计算模型。比如,min()、max() 和 count() 方法,因为常用而被纳入标准库中。事实上,这些方法都是 reduce 操作。
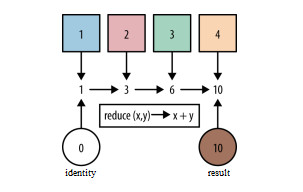
reduce() 方法有三种变形:
T reduce(T identity, BinaryOperator<T> accumulator)
Optional<T> reduce(BinaryOperator<T> accumulator)
<U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner);
以下代码片段使用 reduce() 方法得到所有元素的和并输出:
Optional<Integer> reduce1 = Stream.of(1, 2, 3, 4).reduce((identity, item) -> {
int result = identity + item;
System.out.println("reduce1: identity = " + identity + ",item = " + item + ",result = " + result);
return result;
});
System.out.println("reduce1: " + reduce1.get());
int reduce2 = Stream.of(1, 2, 3, 4).reduce(0, (identity, item) -> {
int result = identity + item;
System.out.println("reduce2: identity = " + identity + ",item = " + item + ",result = " + result);
return result;
});
System.out.println("reduce2: " + reduce2);
从打印结果可以看出,reduce前两种变形,因为接受参数不同,其执行的操作也有相应变化:
- 变形1:未定义初始值,从而第一次执行的时候第一个参数的值是 Stream 的第一个元素,第二个参数是 Stream 的第二个元素
- 变形2:定义了初始值,从而第一次执行的时候第一个参数的值是初始值,第二个参数是 Stream 的第一个元素
sorted()
sorted() 方法用于对 Stream 进行自然顺序排序或比较器规则排序,并返回排序后的新 Stream。
sorted() 方法有两种变形:
Stream<T> sorted()
Stream<T> sorted(Comparator<? super T> comparator)
以下代码片段使用 sorted() 方法进行排序后得到所有元素并输出:
List<Integer> values = Arrays.asList(1,0,2,-1,-10,6,0,-25,90);
// 1. 自然顺序排序
values.stream()
.sorted()
.forEach(System.out::println);
// 2. 比较器顺序排序(自然顺序排序)
values.stream()
.sorted(Comparator.naturalOrder())
.forEach(System.out::println);
// 3. 比较器顺序排序(自然顺序逆序排序)
values.stream()
.sorted(Comparator.reverseOrder())
.forEach(System.out::println);
// 4. 比较器顺序排序(自然顺序逆序排序)
values.stream()
.sorted((Comparator<Integer>) (o1, o2) -> o1.compareTo(o2))
.forEach(System.out::println);
anyMatch()
anyMatch() 方法对于 Stream 中包含的元素使用给定的过滤函数进行匹配操作,Stream 中任意一个元素符合传入的 predicate,返回 true。
以下代码片段使用 anyMatch() 方法判断是否有大于1的元素:
boolean anyMatch = Stream.of(1, 2, 3, 4).anyMatch(value -> value > 1);
if (anyMatch) {
System.out.println("有大于1的元素");
}
allMatch()
allMatch() 方法对于 Stream 中包含的元素使用给定的过滤函数进行匹配操作,Stream 中全部元素符合传入的 predicate,返回 true。
以下代码片段使用 allMatch() 方法判断是否所有元素都大于0:
boolean allMatch = Stream.of(1, 2, 3, 4).allMatch(value -> value > 0);
if (allMatch) {
System.out.println("所有元素都大于0");
}
noneMatch()
noneMatch() 方法对于 Stream 中包含的元素使用给定的过滤函数进行匹配操作,Stream 中没有一个元素符合传入的 predicate,返回 true。
以下代码片段使用 noneMatch() 方法判断是否没有小于0的元素:
boolean noneMatch = Stream.of(1, 2, 3, 4).noneMatch(value -> value < 0);
if (noneMatch) {
System.out.println("没有小于0的元素");
}
Collector
Collector 是 Stream 中对于 Reduce 操作的抽象,此接口中定义了常用的 Reduce 操作,包括:将元素累积到集合中,使用 StringBuilder连接字符串;计算元素相关的统计信息,例如 sum,min,max 或 average 等。Collectors(类收集器)提供了许多常见的可变减少操作的实现。
Collector 中定义的 Reduce 操作可以通过串行或者并行的方式进行实现。BaseStream 接口中的 parallel()、sequential()、unordered() 方法提供的高层 API 使并发程序设计变得非常简洁。
Collector<T, A, R> 接受三个泛型参数,对可变减少操作的数据类型作相应限制:
T:输入元素类型A:缩减操作的可变累积类型(通常隐藏为实现细节)R:可变减少操作的结果类型
Collector 接口声明了4个函数,这四个函数一起协调执行以将元素目累积到可变结果容器中,并且可以选择地对结果进行最终的变换。
Supplier<A> supplier():创建并返回一个新的可变结果容器。BiConsumer<A, T> accumulator():将元素添加到可变结果容器中。BinaryOperator<A> combiner():接收两个结果容器将合并为一个结果容器。Function<A, R> finisher():对结果容器作相应的变换。
在 Collector 接口的 characteristics() 方法内,可以对 Collector 声明相关约束:
Set<Characteristics> characteristics()
而 Characteristics是 Collector 内的一个枚举类,声明了以下三个属性,用来约束Collector的属性:
CONCURRENT:表示此收集器支持并发,意味着允许在多个线程中,累加器可以调用结果容器UNORDERED:表示收集器并不按照 Stream 中的元素输入顺序执行IDENTITY_FINISH:表示 finisher 实现的是识别功能,可以省略。
注意:如果一个容器仅声明
CONCURRENT属性,而不是UNORDERED属性,那么该容器仅仅支持无序的 Stream 在多线程中执行。
Collectors
Collectors 是 Collector 的实现,它实现了各种有用的 Reduce 操作,例如将元素累积到集合中,根据各种标准汇总元素等等。
转换成其他集合
很多 Stream 的链式操作可以转成集合,比如 toList(),生成了 java.util.List 类的实例。当然了,还有还有 toSet() 和 toCollection(Supplier<C> collectionFactory),分别生成 java.util.Set 和 java.util.Collection 类的实例。
toList()
toList() 方法用于返回一个将输入元素累积到一个新的 java.util.List 中的 Collector 实例。代码示例如下:
List<Integer> list = Stream.of(1, 2, 3, 4)
.collect(Collectors.toList());
System.out.println(list);
toSet()
toSet() 方法用于返回一个将输入元素累积到一个新的 java.util.Set 中的 Collector 实例。代码示例如下:
Set<Integer> set = Stream.of(1, 2, 3, 4)
.collect(Collectors.toSet());
System.out.println(set);
toCollection()
toCollection() 方法用于返回一个将输入元素按照遇到的顺序累积到一个新的 java.util.Collection 中的 Collector 实例,java.util.Collection 由提供的工厂创建。
通常情况下,创建集合时需要调用适当的构造函数指明集合的具体类型,但是调用 toList() 或者 toSet() 方法时,不需要指定具体的类型,Stream 类库会自动推断并生成合适的类型。当然,有时候对转换生成的集合有特定要求,比如,希望生成一个 TreeSet,而不是由 Stream 类库自动指定的一种类型。此时使用 toCollection(),它接受一个函数作为参数,来创建集合。代码示例如下:
TreeSet<Integer> treeSet = Stream.of(1, 2, 3, 4)
.collect(Collectors.toCollection(TreeSet::new));
System.out.println(treeSet);
toMap()
toMap() 方法用于返回一个通过提供的映射函数将输入元素生成的键和值累积到一个新的 java.util.Map 中的 Collector 实例。
由于 Map 中有 Key 和 Value 这两个值,故该方法与 toList()、toSet() 等方法的处理方式是不一样的。toMap() 方法最少应接受两个参数,一个用来生成 key,另外一个用来生成 value。toMap() 方法有三种变形:
Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper)
Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper, BinaryOperator<U> mergeFunction)
Collector<T, ?, M> toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper, BinaryOperator<U> mergeFunction, Supplier<M> mapSupplier)
- 类型参数:
T:输入元素的类型K:Key 映射函数的输出类型U:Value 映射函数的输出类型M:生成的 Map 类型
- 参数:
keyMapper:用于生成 Key 的映射函数valueMapper:用于生成 Value 的映射函数mergeFunction:合并函数,用于解决与相同 Key 关联的 Value 之间的冲突mapSupplier:返回一个用于存储结果的新的空 Map 实例
代码示例如下:
List<Person> persons = new ArrayList<>();
persons.add(new Person(1, "Aaron"));
persons.add(new Person(2, "Cherry"));
persons.add(new Person(3, "Jim"));
Map<Integer, String> map = persons.stream()
.collect(Collectors.toMap(Person::getId, Person::getName));
System.out.println(map);
转换成值
使用 collect() 可以将 Stream 转换成值。
averagingDouble():求平均值,Stream 的元素类型为 doubleaveragingInt():求平均值,Stream 的元素类型为 intaveragingLong():求平均值,Stream 的元素类型为 longcounting():Stream 的元素个数maxBy():在指定条件下的,Stream 的最大元素minBy():在指定条件下的,Stream 的最小元素reducing():reduce 操作summarizingInt():统计 Stream 的数据(int)状态,其中包括 count,min,max,sum 和平均。summarizingLong():统计 Stream 的数据(long)状态,其中包括 count,min,max,sum 和平均。summarizingDouble():统计 Stream 的数据(double)状态,其中包括 count,min,max,sum 和平均。summingDouble():求和,Stream 的元素类型为 doublesummingInt():求和,Stream 的元素类型为 intsummingLong():求和,Stream 的元素类型为 long
代码示例如下:
Double collectAveragingDouble = Stream.of(1, 2, 3, 4).collect(Collectors.averagingDouble(value -> value));
System.out.println("collectAveragingDouble : " + collectAveragingDouble);
Optional<Integer> collectMaxBy = Stream.of(1, 2, 3, 4).collect(Collectors.maxBy(Comparator.comparingInt(o -> o)));
System.out.println("collectMaxBy : " + collectMaxBy.get());
DoubleSummaryStatistics collectSummarizingDouble = Stream.of(1, 2, 3, 4).collect(Collectors.summarizingDouble(value -> value));
System.out.println("collectSummarizingDouble : " + collectSummarizingDouble.getSum());
分割数据块
collect() 方法的一个常用操作将 Stream 分解成两个集合。
假如一个数字的 Stream,我们可能希望将其分割成两个集合,一个是偶数集合,另外一个是奇数集合。我们首先想到的就是过滤操作,通过两次过滤操作,很简单的就完成了我们的需求。但是这样操作起来有问题。首先,为了执行两次过滤操作,需要有两个流。其次,如果过滤操作复杂,每个流上都要执行这样的操作, 代码也会变得冗余。
这里就不得不说 Collectors 库中的 partitioningBy() 方法,它接受一个流,并将其分成两部分:使用 Predicate 对象,指定条件并判断一个元素应该属于哪个部分,并根据布尔值返回一个 Map<Boolean, List<T>>。因此对于 key 为 true 所对应的 List 中的元素,满足 Predicate 对象中指定的条件;同样,key 为 false 所对应的 List 中的元素,不满足 Predicate 对象中指定的条件。
代码示例如下:
Map<Boolean, List<Integer>> collectPartitioningBy = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.partitioningBy(it -> it % 2 == 0));
System.out.println("collectPartitioningBy : " + collectPartitioningBy);
数据分组
数据分组是一种更自然的分割数据操作,与将数据分成 true 和 false 两部分不同,可以使用任意值对数据分组。
调用 Stream 的 collect() 方法,传入一个收集器,groupingBy() 方法接受一个分类函数,用来对数据分组,就像 partitioningBy() 方法一样,接受一个 Predicate 对象将数据分成 true 和 false 两部分。使用到的分类器是一个 Function 对象,和 map 操作用到的一样。
代码示例如下:
Map<Boolean, List<Integer>> collectGroupingBy = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.groupingBy(it -> it > 3));
System.out.println("collectGroupingBy : " + collectGroupingBy);
字符串
有时候,需要将 Stream 的元素(String 类型)最后生成一组字符串,可以使用 Collectors.joining() 收集 Stream 中的值,该方法可以方便地将 Stream 得到一个字符串。joining() 函数接受三个参数,分别表示分隔符(用以分隔元素)、前缀和后缀。
代码示例如下:
String joining = Stream.of("1", "2", "3", "4").collect(Collectors.joining(",", "[", "]"));
System.out.println("joining: " + joining);
组合 Collector
Collectors 库中的 partitioningBy() 和 groupingBy() 方法还可以接收一个 Collector,用以收集最终结果的一个子集,这些 Collector 叫作下游收集器。收集器是生成最终结果的一剂配方,下游收集器则是生成部分结果的配方,主收集器中会用到下游收集器。这种组合使用收集器的方式, 使得它们在 Stream 类库中的作用更加强大。
那些为基本类型特殊定制的函数,如 averagingInt()、summarizingLong() 等,事实上和调用特殊 Stream 上的方法是等价的,加上它们是为了将它们当作下游收集器来使用的。
比如要收集各个分组的列表中的元素个数,代码示例如下:
Map<Boolean, Long> collectPartitioningBy = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.groupingBy(it -> it > 3, Collectors.counting()));
System.out.println("collectPartitioningBy : " + collectPartitioningBy);
Map<Boolean, Long> collectGroupingBy = Stream.of(1, 2, 3, 4, 5, 6).collect(Collectors.groupingBy(it -> it > 3, Collectors.counting()));
System.out.println("collectGroupingBy : " + collectGroupingBy);
总结
Stream 的特性可以归纳为:
- Stream 不是数据结构
- Stream 没有内部存储,它只是用操作管道从 source(数据结构、数组、generator function、IO channel)抓取数据。
- Stream 绝不修改自己所封装的底层数据结构的数据。例如 Stream 的 filter 操作会产生一个不包含被过滤元素的新 Stream,而不是从 source 删除那些元素。
- Stream 的所有操作必须以 lambda 表达式为参数
- Stream 不支持索引访问
- Stream 可以请求第一个元素,但无法请求第二个,第三个,或最后一个。不过请参阅下一项。
- Stream 很容易生成数组或者 List
- Stream 的惰性化
- Stream 的很多操作是向后延迟的,一直到它弄清楚了最后需要多少数据才会开始。
- Stream 的Intermediate 操作永远是惰性化的。
- 并行能力
- 当一个 Stream 是并行化的,就不需要再写多线程代码,所有对它的操作会自动并行进行的。
- Stream 可以是无限的,集合有固定大小,Stream 则不必。limit(n) 和 findFirst() 这类的 short-circuiting 操作可以对无限的 Stream 进行运算并很快完成。
相关文档
- Oracle Java 8 官方文档对 java.util.stream package 的说明。
- Java 8 Tutorials, Resources, Books and Examples to learn Lambdas, Stream API and Functional Interfaces。
- 关于 Lambda 和 Stream 更多介绍的教程。



