早在 Java 2 中之前,Java 就提供了特设类。比如:Dictionary、Vector、Stack 和 Properties 这些类用来存储和操作对象组。虽然这些类都非常有用,但是它们缺少一个核心的,统一的主题。由于这个原因,使用 Vector 类的方式和使用 Properties 类的方式有着很大不同。
集合框架被设计成要满足以下几个目标:
- 该框架必须是高性能的,基本集合(动态数组,链表,树,哈希表)的实现也必须是高效的。
- 该框架允许不同类型的集合,以类似的方式工作,具有高度的互操作性。
- 对一个集合的扩展和适应必须是简单的。
为此,整个集合框架就围绕一组标准接口而设计。
集合框架图
Java 集合框架图如下: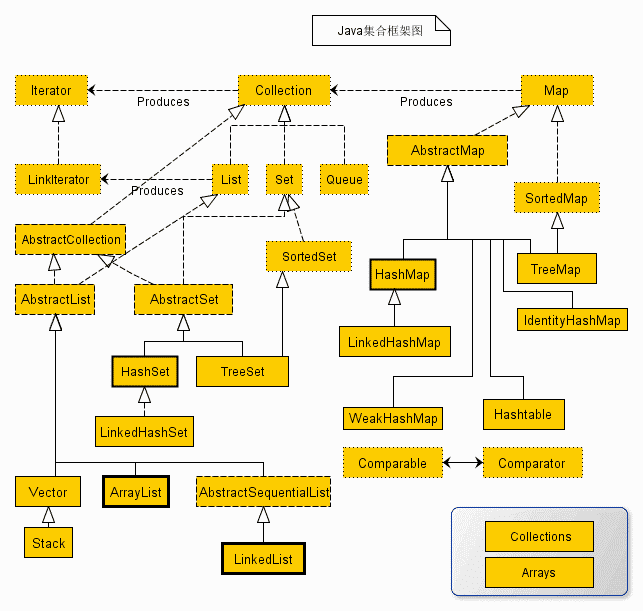
从上面的集合框架图可以看到,Java 集合框架主要包括两种类型的容器:
集合(Collection):存储一个元素集合。Collection 接口又有 3 种子类型,List、Set 和 Queue,再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、TreeSet 等。图(Map):存储键/值对映射。Map 接口又有 3 种子类型,ConcurrentMap、ObservableMap、SortedMap,再下面是一些抽象类,最后是具体实现类,常用的有 HashMap、LinkedHashMap、TreeMap、Hashtable、Properties 等等。
集合框架是一个用来代表和操纵集合的统一架构。所有的集合框架都包含如下内容:
接口:是代表集合的抽象数据类型。例如 Collection、List、Set、Map 等。之所以定义多个接口,是为了以不同的方式操作集合对象实现(类):是集合接口的具体实现。从本质上讲,它们是可重复使用的数据结构,例如:ArrayList、LinkedList、HashSet、HashMap、LinkedHashMap。算法:是实现集合接口的对象里的方法执行的一些有用的计算,例如:搜索和排序。这些算法被称为多态,那是因为相同的方法可以在相似的接口上有着不同的实现。
除了集合,该框架也定义了几个 Map 接口和类。Map 里存储的是键/值对。尽管 Map 不是集合,但是它们完全整合在集合中。
集合关系图
Java Collection UML 类关系图如下: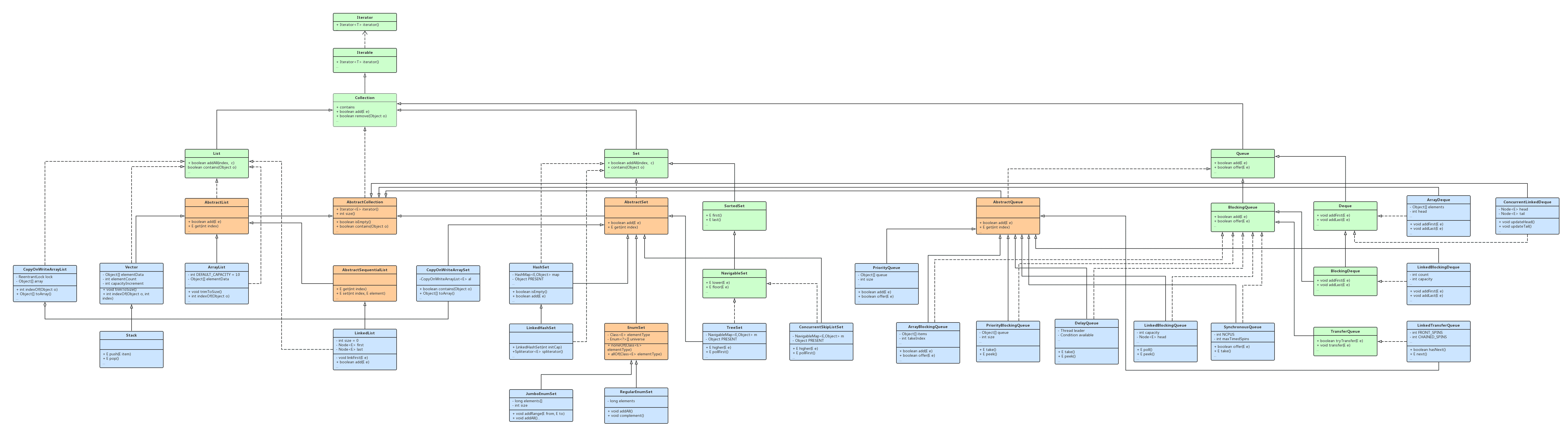
Java Map UML 类关系图如下: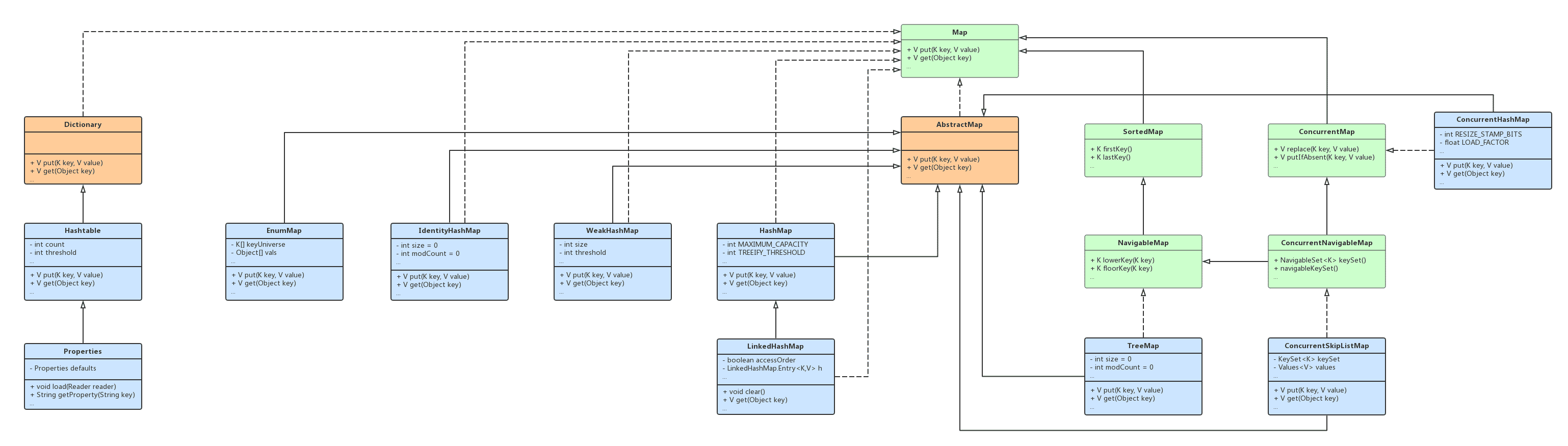
集合接口、类的关系
Collection
Collection 接口继承了 Iterable 接口,依赖了 Predicate、Spliterator、Stream 接口(这些均为 Java8 新增),Iterable 接口依赖了 Iterator 接口。
List接口继承自Collection接口,依赖了UnaryOperator接口(Java8新增)、ListIterator、Comparator接口。Set接口继承自Collection接口。AbstractSet抽象类继承了AbstractCollection抽象类,实现了Set接口。HashSet类继承了AbstractSet抽象类,实现了Set、Cloneable、Serializable接口,聚合了HashMap类。LinkedHashSet类继承了HashSet类,实现了Set、Cloneable、Serializable接口。
TreeSet类继承了AbstractSet抽象类,实现了NavigableSet、Cloneable、Serializable接口,聚合了NavigableMap,依赖了Comparator、SortedSet接口。EnumSet抽象类继承了AbstractSet抽象类,实现了Cloneable、Serializable接口,依赖了Comparator、SortedSet接口。RegularEnumSet类继承了EnumSet抽象类。JumboEnumSet类继承了EnumSet抽象类。
CopyOnWriteArraySet类继承了AbstractSet抽象类,实现了Serializable接口,聚合了CopyOnWriteArrayList类,依赖了Predicate、Consumer接口。ConcurrentSkipListSet类继承了AbstractSet抽象类,实现了NavigableSet、Cloneable、Serializable接口。
SortedSet接口继承自Set接口,依赖了Comparator接口。NavigableSet接口继承自SortedSet接口(Java6新增)。
Queue接口继承了Collection接口。Deque接口继承了Queue接口。BlockingQueue接口继承了Queue接口。BlockingDeque接口继承了BlockingQueue、Deque接口。TransferQueue接口继承了BlockingQueue接口。
AbstractCollection抽象类实现了Collection接口。AbstractList抽象类继承了AbstractCollection抽象类,实现了List接口,依赖了List、RandomAccess、Cloneable、Serializable接口。ArrayList类继承了AbstractList抽象类,实现了List、RandomAccess、Cloneable、Serializable接口。AbstractSequentialList抽象类继承了AbstractList抽象类。LinkedList类继承了AbstractSequentialList抽象类,实现了List、Deque、Cloneable、Serializable接口。CopyOnWriteArrayList实现了List、RandomAccess、Cloneable、Serializable接口。Vector类继承了AbstractList抽象类,实现了List、RandomAccess、Cloneable、Serializable接口。
Stack类继承了Vector类。
AbstractQueue抽象类继承了AbstractCollection接口,实现了Queue接口。SynchronousQueue类继承了AbstractQueue接口,实现了BlockingQueue、Serializable接口,依赖了Collection、Spliterator接口。ArrayBlockingQueue类继承了AbstractQueue接口,实现了BlockingQueue、Serializable接口。LinkedBlockingQueue类继承了AbstractQueue接口,实现了BlockingQueue、Serializable接口。PriorityBlockingQueue类继承了AbstractQueue接口,实现了BlockingQueue、Serializable接口,聚合了Comparator接口,依赖了Collection、Comparator、Comparable接口。DelayQueue类继承了AbstractQueue接口,实现了BlockingQueue接口。LinkedBlockingDeque类继承了AbstractQueue接口,实现了BlockingDeque、Serializable接口。PriorityQueue类继承了AbstractQueue接口。LinkedTransferQueue类继承了AbstractQueue接口,实现了TransferQueue、Serializable接口(Java7新增)。
ConcurrentLinkedDeque类继承了AbstractCollection抽象类,实现了Deque、Cloneable、Serializable接口。ArrayDeque类继承了AbstractCollection抽象类,实现了Deque、Serializable接口。
Map
Map 接口依赖了 Set、Collection、BiConsumer、Function、BiFunction 接口,Map.Entry 是 Map 中的内部接口。
AbstractMap抽象类实现了Map接口,聚合了Collection、Set接口。HashMap类继承了AbstractMap抽象类,实现了Map、Cloneable、Serializable接口,依赖了Collection、Set接口。LinkedHashMap继承了HashMap类,实现了Map接口,依赖了Collection、Set、Consumer、BiConsumer接口。
TreeMap类继承了AbstractMap抽象类,实现了NavigableMap、Cloneable、Serializable接口,依赖了Comparator、SortedMap、Collection、Set、BiConsumer、BiFunction接口。EnumMap类继承了AbstractMap抽象类,实现了Cloneable、Serializable接口,依赖了AbstractSet类,Collection、Set接口。WeakHashMap类继承了AbstractMap抽象类,实现了Map接口,依赖了Collection、Set、Consumer、BiConsumer、BiFunction接口。IdentityHashMap类继承了AbstractMap抽象类,实现了Map、Serializable、Cloneable接口,依赖了Collection、Set、Consumer、BiConsumer、BiFunction接口。ConcurrentHashMap类继承了AbstractMap抽象类,实现了ConcurrentMap、Serializable接口,依赖了Comparable、ParameterizedType、Collection、Set、Spliterator、Consumer、BiConsumer、Function、BiFunction、ToDoubleFunction、DoubleBinaryOperator等接口。ConcurrentSkipListMap类继承了AbstractMap抽象类,实现了ConcurrentNavigableMap、Cloneable、Serializable接口,聚合了Comparator接口,依赖了Collection、Set、Consumer、BiConsumer、BiFunction、NavigableSet接口。
SortedMap接口继承自Map接口,依赖了Set、Collection、Comparator接口。NavigableMap接口继承了SortedMap接口,依赖了NavigableSet接口。ConcurrentNavigableMap接口继承了ConcurrentMap、NavigableMap接口,聚合了NavigableSet接口。
ConcurrentMap接口继承了Map接口,依赖了BiConsumer、BiFunction接口。Hashtable类继承了Dictionary抽象类,实现了Map、Cloneable、Serializable接口,聚合了Collection、Set接口,依赖了Enumeration、BiConsumer、BiFunction接口。Properties类继承了Hashtable类。
工具类
Collections是Collection的辅助工具类,依赖了上述大多数接口和类。Arrays是数组的辅助工具类,依赖了上述一些接口和类。
集合接口、类的功能
Collection
Collection:Collection 是最基本集合接口,它定义了一组允许重复的对象。Collection 接口派生了三个子接口 List、Set和Queue。Collection 所有实现类的遍历都可以使用 Iterator 接口或者是 foreach 来循环。
List:List代表有序、可重复的集合。ArrayList:底层使用数组的形式来实现,排列有序可重复,查询速度快、增删数据慢,线程不安全,效率高。ArrayList创建时的大小为0;当加入第一个元素时,进行第一次扩容时,默认容量大小为10,每次扩容都以当前数组大小的1.5倍去扩容。Vector:底层使用数组的形式来实现,排列有序可重复,查询速度快、增删数据慢,线程安全,效率低。Vector创建时的默认大小为10;Vector每次扩容都以当前数组大小的2倍去扩容。当指定了capacityIncrement之后,每次扩容仅在原先基础上增加capacityIncrement个单位空间。ArrayList和Vector的add、get、size方法的复杂度都为O(1),remove方法的复杂度为O(n)。Stack:Vector的一个子类,是标准的先进后出(FILO, First In Last Out)的栈。底层通过数组实现的,线程安全。
LinkedList:底层使用双向循环链表的数据结构来实现,排列有序可重复,查询速度慢、增删数据快,线程不安全。CopyOnWriteArrayList:底层使用Copy-On-Write的优化策略实现,适用于读多写少的场景,同ArrayList功能相似,线程安全。CopyOnWriteArrayList在某些情况下比Collections.synchronizedList(List list)有更好的性能。缺点是:内存占用大和数据一致性问题,只能保证最终一致性。
Set:Set代表无序、不可重复的集合。HastSet:底层使用Hash表来实现,内部使用了HashMap,排列无序不可重复,存取速度快,线程不安全。LinkedHashSet:底层采用Hash表存储,并用双向链表记录插入顺序,排列有序不可重复,存取速度较HashSet略慢,比TreeSet快,线程不安全。
TreeSet:底层使用红黑树来实现,内部使用了NavigableMap,按自然顺序或者自定义顺序存放、不可重复,线程不安全。CopyOnWriteArraySet:底层使用Copy-On-Write的优化策略实现,适用于读多写少的场景,内部使用了CopyOnWriteArrayList,同HastSet功能相似,线程安全。ConcurrentSkipListSet:底层使用跳跃列表来实现,适用于高并发的场景,内部使用了ConcurrentNavigableMap,同TreeSet功能相似,线程安全。EnumSet:是抽象类,只能用来存储Enum常量或其子类,不能存储其它类型,EnumSet有两种实现方式,RegularEnumSet和JumboEnumSet,但是这两种实现方式是包私有的,不能在包外访问,因此必须使用工厂方法来创建并返回EnumSet实例,不能通过构造函数来创建。EnumSet中提供了多种创建EnumSet实例的静态工厂方法,例如of方法(进行了函数重载),copyOf方法,noneOf方法等。存储效率快,线程不安全。存储枚举常量时使用EnumSet而不要用HashSet。
Queue:Queue是Java 5之后增加的集合体系,表示队列集合的相关实现,大多遵循先进先出(FIFO, First-In-First-Out)的模式。PriorityQueue:即优先队列,底层基于优先堆的一个无界队列来实现,无界但可选容量界限。这个优先队列中的元素可以默认自然排序或者通过提供的Comparator(比较器)在队列实例化的时排序,而不是先进先出。不允许空值、不支持non-comparable(不可比较)的对象,每次从队列中取出的是具有最高优先权的元素,线程不安全。ArrayBlockingQueue:底层基于定长数组的阻塞队列实现,即是线程安全的有界阻塞队列。ArrayBlockingQueue内部通过互斥锁保护竞争资源,实现了多线程对竞争资源的互斥访问。队列中的锁是没有分离的,所以在添加的同时就不能读取,读取的同时就不能添加,所以锁方面性能不如LinkedBlockingQueue。LinkedBlockingQueue:即链接队列,底层基于单向链表的阻塞队列实现,无界但可选容量界限,线程安全。队列中的锁是分离的,即添加用的是putLock,获取是takeLock,所以在添加获取方面理论上性能会高于ArrayBlockingQueue。所以LinkedBlockingQueue更适合实现生产者-消费者队列。PriorityBlockingQueue:即优先阻塞队列,底层基于优先堆的一个无界队列来实现,无界但可选容量界限的阻塞队列,线程安全,功能同PriorityQueue、LinkedBlockQueue相似。其所含对象的排序不是先进先出,而是依据对象的自然排序顺序或者是构造函数的Comparator决定的顺序。SynchronousQueue:即同步队列,是一种线程安全无缓冲的无界阻塞队列。其操作必须是放和取交替完成的,即每个put必须等待一个take,反之亦然。DelayQueue:即延迟队列,是一种有序无界阻塞队列,只有在延迟期满时才能从中提取元素,线程安全。ArrayDeque:底层采用了循环数组的方式来完成双端队列的实现,无限扩展且可选容量。Java 已不推荐使用Stack,而是推荐使用更高效的ArrayDeque来实现栈的功能,非线程安全。LinkedBlockingDeque:底层采用了双向链表实现的双端阻塞并发队列,无限扩展且可选容量。该阻塞队列同时支持FIFO和FILO两种操作方式,即可以从队列的头和尾同时操作(插入/删除),且线程安全。ConcurrentLinkedDeque:底层采用了双向链表实现的双端非阻塞并发队列,无限扩展且可选容量。该队列同时支持FIFO和FILO两种操作方式,即可以从队列的头和尾同时操作(插入/删除),且线程安全。LinkedTransferQueue:底层采用了单向链表实现的无界传输阻塞队列,先进先出,无限扩展且可选容量线程安全。
Map
Map:Map 代表具有映射关系的集合。
HashMap:底层是用链表数组,Java8后又加了红黑树来实现,键无序不可重复可为 null、值可重复可为 null,存取速度快,线程不安全。LinkedHashMap:底层是用链表数组存储,并用双向链表记录插入顺序,键有序不可重复可为 null、值可重复可为 null,存取速度快较HashMap略慢,比TreeMap快,线程不安全。
HashTable:底层是用链表数组,键无序不可重复可为 null、值可重复可为 null,存取速度较HashMap慢,线程安全。Properties:是HashTable的子类,是 <String,String> 的映射,比HashTable多了load、store两个方法,线程安全。
TreeMap:底层使用红黑树来实现,内部使用了Comparator,按自然顺序或自定义顺序存放键,键不可重复不可为 null、值可重复可为 null,存取速度较HashMap慢,线程不安全。EnumMap:底层使用数组来实现,是专门为枚举类型量身定做的 Map,性能更好。只能接收同一枚举类型的实例作为键值,并且由于枚举类型实例的数量相对固定并且有限,所以EnumMap使用数组来存放与枚举类型对应的值,线程不安全。WeakHashMap:同HashMap基本相似。区别在于,HashMap的key保留对象的强引用,这意味着只要该HashMap对象不被销毁,该HashMap对象所有 key 所引用的对象不会被垃圾回收,HashMap也不会自动删除这些key所对应的key-value对象;但WeakHashMap的key只保留对实际对象的弱引用,这意味着当垃圾回收了该key所对应的实际对象后,WeakHashMap会自动删除该key对应的key-value对象。IdentityHashMap:同HashMap基本相似。区别在于,在处理两个key相等时,对于普通HashMap而言,只要key1和key2通过equals比较返回true时就认为 key 相同;在IdentityHashMap中,当且仅当两个key严格相等时(key1 = key2)时才认为两个key相同。ConcurrentHashMap:底层使用锁分段技术来实现线程安全,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护者一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。ConcurrentSkipListMap:底层使用跳跃列表来实现,适用于高并发的场景,内部使用了ConcurrentNavigableMap,同TreeMap功能相似,是一个并发的、可排序的 Map,线程安全。因此它可以在多线程环境中弥补ConcurrentHashMap不支持排序的问题。
思维导图
Java 集合框架功能介绍思维导图如下:
集合接口、类的方法
Collection 接口中的抽象方法
| 方法 | 描述 |
|---|---|
int size() |
返回集合的大小 |
boolean isEmpty() |
返回集合是否为空的布尔值 |
boolean contains(Object o) |
返回集合是否包含元素 o 的布尔值 |
Iterator<E> iterator() |
返回该集合中元素的迭代器,继承自 Iterable 接口 |
Object[] toArray() |
返回一个包含此集合中所有元素的数组 |
<T> T[] toArray(T[] a) |
返回一个包含此集合中所有元素的数组,返回类型由传入数组参数的类型决定 |
boolean add(E e) |
返回向集合中插入元素 e 是否成功的布尔值 |
boolean remove(Object o) |
返回从集合中删除元素 o 是否成功的布尔值 |
boolean containsAll(Collection<?> c) |
返回本集合中是否完全包含集合 c 的布尔值,即判断集合 c 是否是本集合子集 |
boolean addAll(Collection<? extends E> c) |
将集合 c 中的所有元素添加到本集合中并返回 |
boolean removeAll(Collection<?> c) |
移除本集合中所有包含集合 c 的所有元素 |
default boolean removeIf(Predicate<? super E> filter) |
Java8 新增的接口默认方法。将会批量删除符合 filter 条件的所有元素,该方法需要一个 Predicate 对象作为作为参数,Predicate 也是函数式接口,因此可使用 Lambda 表达式作为参数 |
boolean retainAll(Collection<?> c) |
返回本集合和集合 c 中相同的元素并存到本集合中,集合 c 保持不变,返回值表示的是本集合是否发生过改变。即该方法是用来求两个集合的交集,交集的结果存到本集合中,如果本集合没发生变化则返回 true |
void clear() |
清空本集合中的所有元素 |
boolean equals(Object o) |
返回本集合是否和对象 o 相等的布尔值 |
int hashCode() |
返回此集合的 Hash 码值 |
default Spliterator<E> spliterator() |
在集合中创建 Spliterator 对象 |
default Stream<E> stream() |
返回一个顺序的 Stream 对象。Java8 引入了 Stream 以实现对集合更方便地进行函数式编程。 |
default Stream<E> parallelStream() |
返回一个可能并行的 Stream 对象。Java8 新增的方法。流可以是顺序的也可以是并行的。顺序流的操作是在单线程上执行的,而并行流的操作是在多线程上并发执行的。 |
List 接口中的额外抽象方法
| 方法 | 描述 |
|---|---|
boolean addAll(int index, Collection<? extends E> c) |
将指定集合 c 中的所有元素插入到指定索引位置处 |
default void replaceAll(UnaryOperator<E> operator) |
Java8 新增的使用 Lambda 的方式,通过应用 UnaryOperator 获得的结果来替换列表中的每个元素 |
default void sort(Comparator<? super E> c) |
在比较器的基础上将本列表排序 |
E get(int index) |
获取本集合中指定索引位置处的元素 |
E set(int index, E element) |
设置或替换本集合中指定索引位置处的元素 |
void add(int index, E element) |
在本集合中的指定索引位置处插入指定的元素 |
E remove(int index) |
移除本集合中指定索引位置处的元素 |
int indexOf(Object o) |
返回指定元素第一次出现的索引位置 |
int lastIndexOf(Object o) |
返回指定元素最后出现的索引位置 |
ListIterator<E> listIterator() |
返回本集合中的 ListIterator 迭代器 |
ListIterator<E> listIterator(int index) |
返回本集合中从指定索引位置开始的 ListIterator 迭代器 |
List<E> subList(int fromIndex, int toIndex) |
返回指定开始和结束索引位置的子集合 |
Set 接口中的额外抽象方法
Set 除了继承自 Collection 的方法之外,没有额外抽象方法。
Map 接口中的抽象方法
| 方法 | 描述 |
|---|---|
boolean containsKey |
判断本 Map 集合中是否包含指定的 key 键 |
boolean containsValue |
判断本 Map 集合中是否包含指定的 value 值 |
V get(Object key) |
根据 key 获取本 Map 集合中的 value 值 |
V put(K key, V value) |
向本 Map 集合中存放 key 键和 value 值,返回 value 值 |
V remove(Object key) |
根据 key 删除本 Map 集合中的 key 和 value 值,并返回删除的 value值 |
void putAll(Map<? extends K, ? extends V> m) |
将指定的 Map 集合添加到本的 Map 集合当中 |
Set<K> keySet() |
获取本 Map 集合中的所有 key 值,并以 Set 接口的结果作为返回 |
Collection<V> values() |
获取本 Map 集合中的所有 value 值,并以 Collection 接口的结果作为返回 |
Set<Map.Entry<K, V>> entrySet() |
获取本 Map 集合中的所有 key 和 value 值,并以 Set<Map.Entry<K, V>> 的结果作为返回 |
default V getOrDefault(Object key, V defaultValue) |
根据 key 获取本 Map 集合中的 value 值,如果没找到对应的值或者 value 值是 null,则返回 defaultValue 的值 |
default void forEach(BiConsumer<? super K, ? super V> action) |
Java8 新增的使用 Lambda 的方式遍历操作 Map 中的元素的默认接口方法 |
default void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) |
Java8 新增的使用 Lambda的方式遍历替换 Map 中的元素的默认接口方法 |
default V putIfAbsent(K key, V value) |
Java8 新增的不用写是否为 null 值的检测语句向 Map 中保存 key 和 value 的元素的默认接口方法,即如果通过 key 获取到的 value 是空的,则在调用 put(key, value) 方法并返回 value 值 |
default boolean remove(Object key, Object value) |
Java8 新增的默认接口方法,删除给定 key 所对应的元素,如果 value 不存在、为 null 或者与参数中的 value 不等,则不能删除。即删除操作需要满足给定的值需要和 map 中的值相等的条件 |
default boolean replace(K key, V oldValue, V newValue) |
Java8 新增的默认接口方法,替换给定 key 所对应的元素,如果 value 不存在、为 null 或者与参数中的 oldValue 不等,则不能替换。即替换操作需要满足给定的值需要和 map 中的值相等的条件 |
default V replace(K key, V value) |
Java8 新增的默认接口方法,替换给定 key 所对应的元素,如果 value 不为 null,则 value 值与参数中的 value 值做替换 |
default V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction) |
Java8 新增的默认接口方法,根据key获取到的 value 如果不为 null,则直接返回 value 值,否则将 Lambda 表达式中的结果值存放到 Map 中 |
default V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) |
Java8 新增的默认接口方法,根据 key获取到的 value 和新计算的值如果不为 null,则直接新计算的值,否则移除该 key,且返回 null |
default V compute(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction) |
Java8 新增的默认接口方法,将 Lambda 表达式中的结果值存放到Map中,如果计算的新值为 null 则返回 null,且移除以前有的 key 和 value 值 |
default V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction) |
Java8 新增的默认接口方法,将新计算的值覆盖 Map 中原 key 对应的 value 值 |
SortedSet接口中的额外抽象方法
| 方法 | 描述 |
|---|---|
Comparator<? super E> comparator() |
返回本 SortedSet 集合中的 Comparator 比较器 |
SortedSet<E> subSet(E fromElement, E toElement) |
获取开始元素和结束元素之间的子 SortedSet 集合 |
SortedSet<E> headSet(E toElement) |
获取开始元素和 toElement 元素之间的子 SortedSet 集合 |
SortedSet<E> tailSet(E fromElement) |
获取 fromElement 元素和结束元素之间的子 SortedSet 集合 |
E first() |
获取本 SortedSet 集合中的第一个元素 |
E last() |
获取本 SortedSet 集合中的最后一个元素 |
SortedMap接口中的额外抽象方法
| 方法 | 描述 |
|---|---|
Comparator<? super K> comparator() |
返回本 SortedMap 集合中的 Comparator 比较器 |
SortedMap<K,V> subMap(K fromKey, K toKey) |
获取开始 key 和结束 key 之间的子 SortedMap 集合 |
SortedMap<K,V> headMap(K toKey) |
获取开始 key 和 toKey 元素之间的子 SortedMap 集合 |
SortedMap<K,V> tailMap(K fromKey) |
获取 fromKey 元素和结束key之间的子 SortedMap 集合 |
K firstKey() |
获取本 SortedMap 集合中的第一个 key |
K lastKey() |
获取本 SortedMap 集合中的最后一个 key |
Set<K> keySet() |
获取本 SortedMap 集合中所有 key 的 Set 集合 |
Collection<V> values() |
获取本 SortedMap 集合中所有 value 的 Collection 集合 |
Set<Map.Entry<K, V>> entrySet() |
获取本 SortedMap 集合中所有 key 和 value 的 Map 集合 |



