模式动机
在软件开发中,我们经常需要使用聚合对象来存储一系列数据。聚合对象拥有两个职责:一是存储数据;二是遍历数据。从依赖性来看,前者是聚合对象的基本职责;而后者既是可变化的,又是可分离的。因此,可以将遍历数据的行为从聚合对象中分离出来,封装在一个被称之为“迭代器”的对象中,由迭代器来提供遍历聚合对象内部数据的行为,这将简化聚合对象的设计,更符合“单一职责原则”的要求。这就是迭代器模式的动机。
模式定义
迭代器模式(Iterator Pattern)提供一种方法来访问聚合对象,而不用暴露这个对象的内部表示,其别名为游标(Cursor)。
迭代器模式是一种
对象行为型模式。
模式结构
角色组成
迭代器模式包含如下角色:
Iterator(抽象迭代器):它定义了访问和遍历元素的接口,声明了用于遍历数据元素的方法,例如:用于获取第一个元素的 first() 方法,用于访问下一个元素的 next() 方法,用于判断是否还有下一个元素的 hasNext() 方法,用于获取当前元素的 currentItem() 方法等,在具体迭代器中将实现这些方法。ConcreteIterator(具体迭代器):它实现了抽象迭代器接口,完成对聚合对象的遍历,同时在具体迭代器中通过游标来记录在聚合对象中所处的当前位置,在具体实现时,游标通常是一个表示位置的非负整数。Aggregate(抽象聚合类):它用于存储和管理元素对象,声明一个 createIterator() 方法用于创建一个迭代器对象,充当抽象迭代器工厂角色。ConcreteAggregate(具体聚合类):它实现了在抽象聚合类中声明的 createIterator() 方法,该方法返回一个与该具体聚合类对应的具体迭代器 ConcreteIterator 实例。
结构图
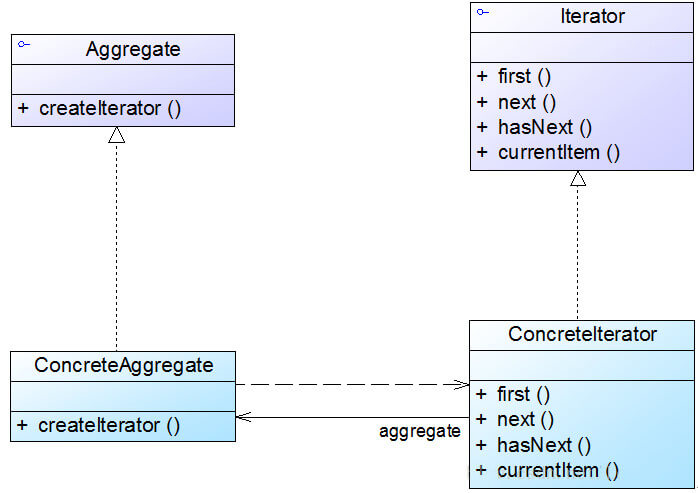
示例代码
首先,是抽象迭代器和具体迭代器。Iterator 接口充当抽象迭代器,ConcreteIterator 类充当具体迭代器,完整代码如下所示:
/**
* 抽象迭代器
*/
interface Iterator {
/**
* 将游标指向第一个元素
*/
void first();
/**
* 将游标指向下一个元素
*/
void next();
/**
* 判断是否存在下一个元素
*/
boolean hasNext();
/**
* 获取游标指向的当前元素
*/
Object currentItem();
}
在抽象迭代器中声明了用于遍历聚合对象中所存储元素的方法。
/**
* 具体迭代器
*/
public class ConcreteIterator implements Iterator {
/** 定义一个游标,用于记录当前访问位置 */
private int cursor;
/** 维持一个对具体聚合对象的引用,以便于访问存储在聚合对象中的数据 */
private ConcreteAggregate aggregate;
public ConcreteIterator(ConcreteAggregate aggregate) {
this.aggregate = aggregate;
}
@Override
public void first() {
// 具体实现代码
}
@Override
public void next() {
// 具体实现代码
}
@Override
public boolean hasNext() {
// 具体实现代码
}
@Override
public Object currentItem() {
// 具体实现代码
}
}
在具体迭代器中将实现抽象迭代器声明的遍历数据的方法。需要注意的是抽象迭代器接口的设计非常重要,一方面需要充分满足各种遍历操作的要求,尽量为各种遍历方法都提供声明,另一方面又不能包含太多方法,接口中方法太多将给子类的实现带来麻烦。因此,可以考虑使用抽象类来设计抽象迭代器,在抽象类中为每一个方法提供一个空的默认实现。如果需要在具体迭代器中为聚合对象增加全新的遍历操作,则必须修改抽象迭代器和具体迭代器的源代码,这将违反“开闭原则”,因此在设计时要考虑全面,避免之后修改接口。
然后,是抽象聚合类和具体聚合类。Aggregate 接口充当抽象聚合类,ConcreteAggregate 类充当具体聚合类,完整代码如下所示:
/**
* 抽象聚合类
*/
interface Aggregate {
Iterator createIterator();
}
聚合类用于存储数据并负责创建迭代器对象。
/**
* 具体聚合类
*/
class ConcreteAggregate implements Aggregate {
public Iterator createIterator() {
return new ConcreteIterator(this);
}
// 下面是业务逻辑代码
......
}
具体聚合类作为抽象聚合类的子类,一方面负责存储数据,另一方面实现了在抽象聚合类中声明的工厂方法 createIterator(),用于返回一个与该具体聚合类对应的具体迭代器对象。
最后,是客户端场景类,完整代码如下所示:
public class IteratorClient {
public static void main(String[] args) {
ConcreteAggregate aggregate = new ConcreteAggregate();
aggregate.add(new BigDecimal(1));
aggregate.add(new BigDecimal(2));
aggregate.add(new BigDecimal(3));
aggregate.add(new BigDecimal(4));
aggregate.add(new BigDecimal(5));
Iterator iterator = aggregate.createIterator();
while (iterator.hasNext()) {
System.out.println(iterator.currentItem());
iterator.next();
}
}
}
除了使用关联关系外,为了能够让迭代器可以访问到聚合对象中的数据,我们还可以将迭代器类设计为聚合类的内部类,JDK 中的迭代器类就是通过这种方法来实现的。
JDK 中的迭代器模式
为了让开发人员能够更加方便地操作聚合对象,在 Java、C# 等编程语言中都提供了内置迭代器。在 Java 集合框架中,常用的 List 和 Set 等聚合类都继承(或实现)了 java.util.Collection 接口。 JDK 中定义了抽象迭代器接口 java.util.Iterator。
在 JDK 中,Collection 接口和 Iterator 接口充当了迭代器模式的抽象层,分别对应于抽象聚合类和抽象迭代器,而 Collection 接口的子类充当了具体聚合类。
Collection 接口
在 java.util.Collection 接口中声明了如下方法(部分方法):
| 方法名 | 方法描述 |
|---|---|
| size() | 用于返回集合中元素的数量 |
| isEmpty() | 用于判断集合中元素是否为空 |
| contains(Object o) 和 containsAll(Collection<?> c) | 用于判断集合中是否包含指定元素 |
| add(E e) 和 addAll(Collection<? extends E> c) | 用于向集合中添加元素 |
| remove(Object o) 和 removeAll(Collection<?> c) | 用于从集合中删除元素 |
| iterator() | 用于返回一个迭代器对象 |
| clear() | 用于清空集合中的元素 |
除了包含一些增加元素和删除元素的方法外,还提供了一个 iterator() 方法,用于返回一个 Iterator 迭代器对象,以便遍历聚合中的元素;具体的 Java 聚合类可以通过实现该 iterator() 方法返回一个具体的 Iterator 对象。
Iterator 接口
在 java.util.Iterator 接口中声明了如下方法(部分方法):
| 方法名 | 方法描述 |
|---|---|
| hasNext() | 用于判断聚合对象中是否还存在下一个元素 |
| next() | 用于将游标移至下一个元素并返回该元素 |
| remove() | 用于删除上次调用 next() 时所返回的元素 |
模式分析
- 在迭代器模式中,提供了一个外部的迭代器来对聚合对象进行访问和遍历,迭代器定义了一个访问该聚合元素的接口,并且可以跟踪当前遍历的元素,了解哪些元素已经遍历过而哪些没有。迭代器的引入,将使得对一个复杂聚合对象的操作变得简单。
- 迭代器模式是一种使用频率非常高的设计模式,通过引入迭代器可以将数据的遍历功能从聚合对象中分离出来,聚合对象只负责存储数据,而遍历数据由迭代器来完成。
优点
迭代器模式的主要优点如下:
- 它支持以不同的方式遍历一个聚合对象,在同一个聚合对象上可以定义多种遍历方式。在迭代器模式中只需要用一个不同的迭代器来替换原有迭代器即可改变遍历算法,我们也可以自己定义迭代器的子类以支持新的遍历方式。
- 迭代器简化了聚合类。由于引入了迭代器,在原有的聚合对象中不需要再自行提供数据遍历等方法,这样可以简化聚合类的设计。
- 在迭代器模式中,由于引入了抽象层,增加新的聚合类和迭代器类都很方便,无须修改原有代码,满足“开闭原则”的要求。
缺点
迭代器模式的主要缺点如下:
- 由于迭代器模式将存储数据和遍历数据的职责分离,增加新的聚合类需要对应增加新的迭代器类,类的个数成对增加,这在一定程度上增加了系统的复杂性。
- 抽象迭代器的设计难度较大,需要充分考虑到系统将来的扩展,例如 JDK 内置迭代器 Iterator 就无法实现逆向遍历,如果需要实现逆向遍历,只能通过其子类 ListIterator 等来实现,而 ListIterator 迭代器无法用于操作 Set 类型的聚合对象。在自定义迭代器时,创建一个考虑全面的抽象迭代器并不是件很容易的事情。
适用环境
在以下情况下可以使用迭代器模式:
- 访问一个聚合对象的内容而无须暴露它的内部表示。将聚合对象的访问与内部数据的存储分离,使得访问聚合对象时无须了解其内部实现细节。
- 需要为一个聚合对象提供多种遍历方式。
- 为遍历不同的聚合结构提供一个统一的接口,在该接口的实现类中为不同的聚合结构提供不同的遍历方式,而客户端可以一致性地操作该接口。
总结
- 迭代器模式提供一种方法来访问聚合对象,而不用暴露这个对象的内部表示,其别名为游标(Cursor)。迭代器模式是一种对象行为型模式。
- 迭代器模式包含四个角色:目标又称为主题,它是指被观察的对象;具体目标是目标类的子类,通常它包含有经常发生改变的数据,当它的状态发生改变时,向它的各个观察者发出通知;观察者将对观察目标的改变做出反应;在具体观察者中维护一个指向具体目标对象的引用,它存储具体观察者的有关状态,这些状态需要和具体目标的状态保持一致。
- 迭代器模式是一种使用频率非常高的设计模式,通过引入迭代器可以将数据的遍历功能从聚合对象中分离出来,聚合对象只负责存储数据,而遍历数据由迭代器来完成。
- 迭代器模式支持以不同的方式遍历一个聚合对象,在同一个聚合对象上可以定义多种遍历方式。在迭代器模式中只需要用一个不同的迭代器来替换原有迭代器即可改变遍历算法,我们也可以自己定义迭代器的子类以支持新的遍历方式。
- 迭代器简化了聚合类。由于引入了迭代器,在原有的聚合对象中不需要再自行提供数据遍历等方法,这样可以简化聚合类的设计。
- 迭代器模式中由于引入了抽象层,增加新的聚合类和迭代器类都很方便,无须修改原有代码,满足“开闭原则”的要求。
- 在 JDK 的
java.util包中,提供了Collection接口以及Iterator接口,它们构成了 Java 语言对迭代器模式的支持。



